
Kirk Marple
As we have seen with Retrieval Augmented Generation (RAG), integrating LLMs with unstructured data can be valuable for a wide range of use cases.
Businesses have gathered years of domain knowledge in silos like Microsoft SharePoint, email, Slack, Microsoft Teams, and Zoom recordings, and they want to explore the hidden relationships between people, organizations, places, and events to provide deeper insights to aid day-to-day decision making.
Knowledge graphs are a perfect fit for modeling these relationships, and LLMs can be used to extract both the entities and their inter-relationships.
In addition, knowledge graphs can be used as context for the RAG pipeline, in addition to content retrieved by 'classic' embeddings-based semantic search
We have published a sample application on GitHub, which shows how we can build a knowledge graph automatically using OpenAI GPT-4o for entity extraction.
You can run the demo yourself here, and log into your SharePoint account to ingest files - documents, audio, images, etc. It requires a free signup on our Developer Portal to get the required keys.
Below is a knowledge graph, with entities automatically extracted from a set of sample data found in a SharePoint folder.
We have used Graphlit to automatically extract images from PDFs, and are using the OpenAI GPT-4 Vision model to perform OCR and generate detailed text descriptions of the images.
Entity extraction is perfomed, not just on textual content, but across multimodal content as well - audio transcripts, image descriptions, etc.
Here we can see the entities extracted from my appearance on the Data Engineering Podcast.
You can see that it has extracted a number of 'organization' entities such as Microsoft, GitHub and Figma, which were discussed on the podcast. These entities were extracted from the audio transcript, which was automatically generated by Graphlit using a Deepgram transcription model.
Most of the entities could be considered 'tags' on the podcast content, and while interesting to visualize, they are valuable to the cataloging of the content - and will be key later for the retrieval element of GraphRAG.
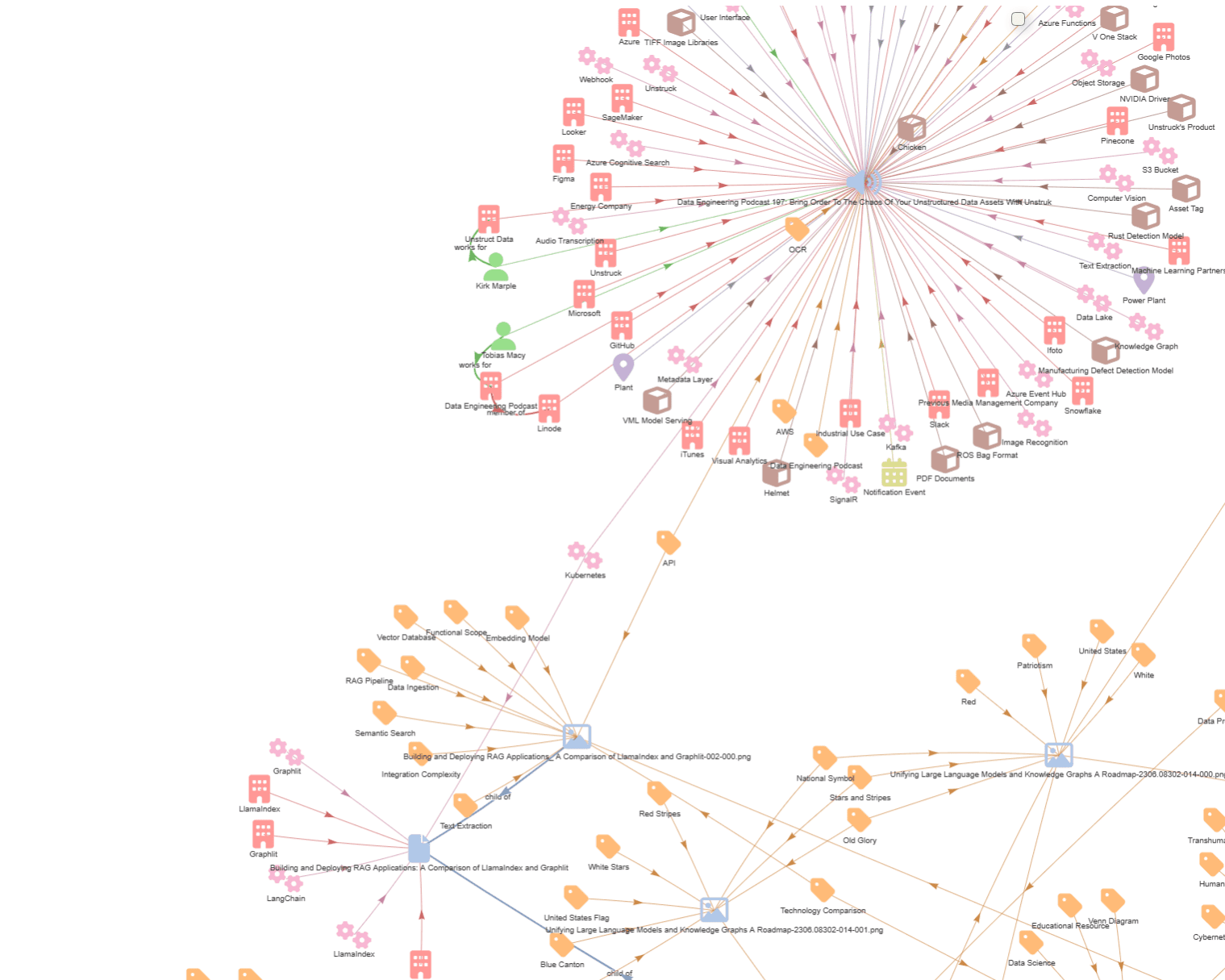
As for focus further in on the relationships, we can see that it found that I (Kirk Marple) work for Unstruct (sic) Data, and Tobias Macy (sic) works for the Data Engineering Podcast, which is a member of Linode. Now, the LLM has identified 'member of' as the relationship, while I believe Linode is actually a sponsor of the podcast.
Extracted entities still need to be reviewed either by humans, or evaluated with other LLMs, possibly fine-tuned on the domain of interest.
Also, entity resolution - or deduplication - is an important step to increase the quality of your knowledge graph relationships by removing duplicate nodes or edges, and by merging similar nodes together (or splitting nodes into separate nodes).